[금융전략을 위한 머신러닝] 7. 자연어 처리
아래 내용은 “금융전략을 위한 머신러닝” 책을 공부하며 정리한 내용입니다.
Chapter 10. 자연어 처리
이론 및 개념
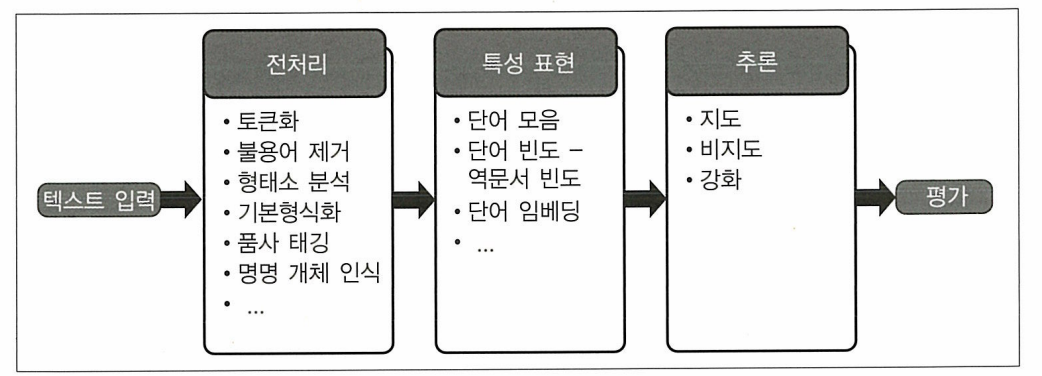 자연어 처리 파이프라인
자연어 처리 파이프라인
전처리
토큰화
토큰화는 텍스트를 토큰이라고 하는 의미 있는 세그먼트로 분할하는 작업이다.
세그먼트는 문장의 구성요소인 단어, 구두점, 숫자 또는 기타 특수 문자일 수 있다.
불용어 제거
모델링에 값을 거의 제공하지 않는 매우 일반적인 단어는 종종 어휘에서 제외하는데, 이러한 단어를 불용어라고 한다.
형태소 분석
형태소 분석은 변형된 단어를 어간, 어기 또는 어근 형식으로 줄이는 과정이다.
기본 형식화
형태소 분석을 약간 번형한 것.
형태소 분석은 종종 존재하지 않는 단어를 생성하는 반면 기본형은 실제단어이다.
품사 태깅
PoS는 문장에서의 역할을 이해하기 위해 문법 범주에 토큰을 할당하는 과정이다.
명명 개체 인식
텍스트에서 명명된 개체를 찾아 미리 정의된 범주로 분류하려는 데이터 전처리에서 선택적 단계이다.
특성 표현
단어 모음 - 단어 수
자연어 처리에서 텍스트에서 특성을 추출하는 일반적인 기술은 텍스트에서 발생한 모든 단어를 버킷에 배치하는 것이다.
텍스트 모음에서 단일 행렬을 만들고 각 행은 토큰을 나타내고 각 열은 말뭉치의 문서 또는 문장을 나타낸다. 행렬의 값은 나타나는 토큰의 인스턴스 수를 나타낸다.
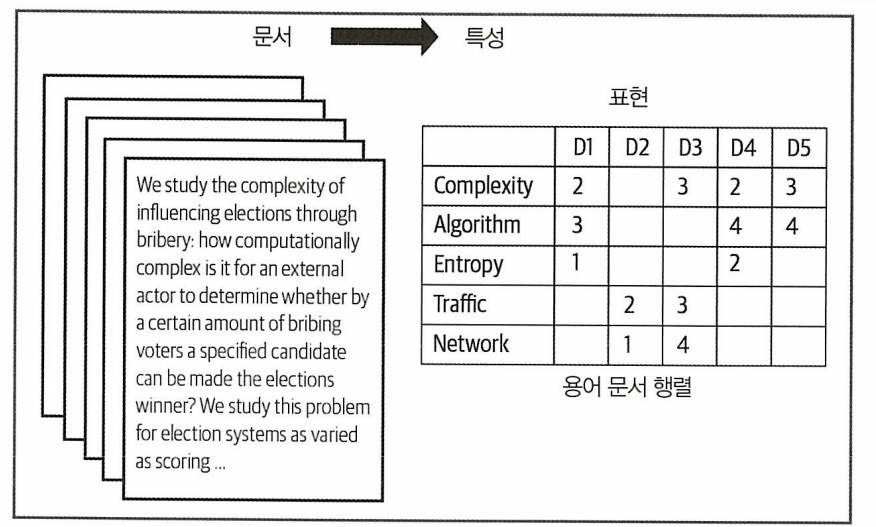 단어 모음
단어 모음
단어 빈도 - 역문서 빈도(TF-IDF)
단어 빈도를 계산하는 것.
단어 임베딩
조밀한 벡터 표현을 사용해 단어와 문서를 타나내는 것.
추론
지도 학습: Naive Bayes
주어진 샘플의 범주를 예측하는 데 사용되며 특성이 다른 특성과 서로 독립적이라는 단순한 가정인 알고리즘.
비지도 학습: LDA
주제를 선택해 문서를 생성한 다음 각 주제에 대해 일련의 단어를 선택해 문서를 생성
이 과정을 리버스 엔지니어링하여 문서에서 주제를 찾는다.
This post is licensed under CC BY 4.0 by the author.