데이터 탐색과 시각화
아래 내용은 “데이터 분석가가 반드시 알아야 할 모든 것” 책을 공부하며 정리한 내용입니다.
1. EDA
EDA란 Exploratory Data Analysis, 탐색적 데이터 분석을 의미한다.
이때 기술통계와 데이터 시각화를 통해 데이터의 특성을 파악한다.
극단적인 해석은 피해야하며 지나친 추론이나 자의적 해석도 지양해야 한다.
1-1. EDA 주요 목적
- 데이터의 형태와 척도가 분석에 알맞게 되어있는지 확인(sanity checking)
- 데이터의 평균, 분산, 분포, 패턴 등의 확인을 통해
- 데이터 특성 파악
- 데이터의 결측값이나 이상치 파악 및 보완
- 변수 간의 관계성 파악
- 분석 목적과 방향성 점검 및 보정
1-2. EDA 실습
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 데이터 불러오기
df = pd.read_csv("파일명")
# 데이터 샘플 확인
df.head()
# 각 컬럼의 속성 및 결측치 확인
df.info()
# 각 컬럼의 통계치 확인
df.describe()
# 각 컬럼의 왜도 확인
df.skew()
# 각 컬럼의 첨도 확인
df.kurtosis()
2. 공분산과 상관성 분석
데이터 탐색과정에서 타겟변수 Y와 입력변수 X와의 관계는 물론 입력변수 X들 간의 관계도 살펴봐야 한다.
이를 통해 독립변수의 변화에 따른 종속 변수의 변화량을 크게 하여 통계적 정확도를 감소시키는 다중공선성을 방지할 수 있으며, 데이터에 대한 이해도를 높일 수 있다.
변수 간의 상관관계를 파악하는 대표적인 개념으로 공분산과 상관계수가 있다. 이를 아래에서 다뤄보도록 하자.
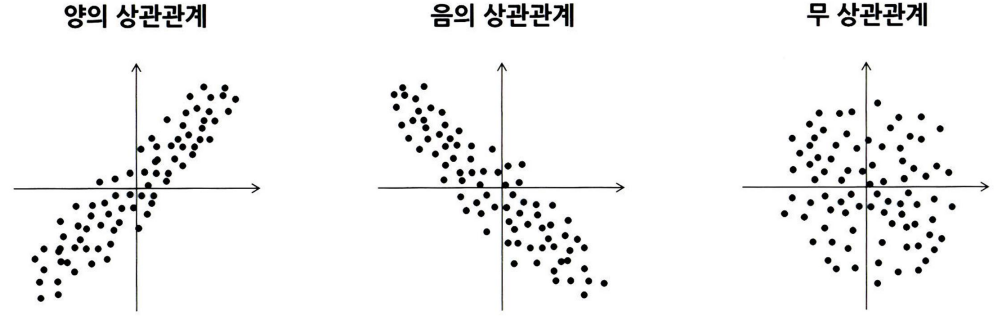 상관관계 예시
상관관계 예시
2-1. 공분산
공분산과 상관계수는 각 변수의 변동이 얼마나 닮았는지를 표현한다는 점에서 같지만, 계산방식에서 차이가 있다.
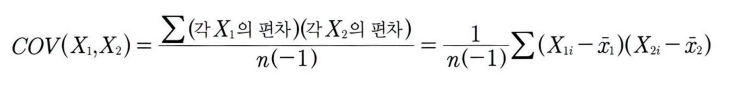 공분산 수식
공분산 수식
공분산의 값에 따라 양, 음, 무, 직선의 상관 관계를 가진다.
그러나 공분산은 각 변수간의 다른 척도기준이 그대로 반영되어 공분산 값이 지니는 크기가 상관성의 정도를 나타내지 못한다.
예를 들어 공분산이 1300이 800보다 상관관계가 크다고 할 수 없다 !!
2-2. 상관계수
공분산의 문제를 해결하기 위해 정규화를 거쳐 상관성을 비교하는 대표적 예시가 피어슨 상관계수이다.
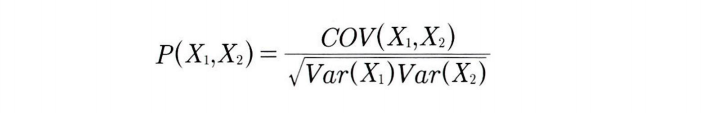 상관계수 수식
상관계수 수식
일반적으로, 계수의 절대값은 1을 넘을 수 없으며 절댓값이 0.7 이상일때 상관 관계가 매우 높고 0.4 이상이면 어느 정도 상관관계가 있다고 해석한다.
 상관계수 예시
상관계수 예시
상관도를 위와 같이 산점도와 함께 보면 상관관계 수준에 따른 데이터 형태를 확인 할 수 있다.
그러나 산점도의 기울기와 상관계수는 관련이 없다!
분산의 관계성이 같다면, 기울기가 크든 작든 상관계수는 같다.
상관계수가 높다는 것은 특정 X에 따른 Y 변화량이 높아진다는 것이 아니라, Y를 예상할 수 있는 정확도 즉 설명력이 높다는 것이다.
3. 시간 시각화
시점 요소가 있는 데이터는 시계열 형태로 표현할 수 있으며, 이를 통해 데이터의 트렌드나 노이즈도 쉽게 찾아 낼 수 있다.
시간 시각화는 선그래프 형태인 연속형과 막대그래프 형태인 분절형으로 구분 할 수 있다.
3-1. 연속형 그래프
선그래프는 시간 간격의 밀도가 높을 때 사용한다. 그러나 데이터의 양이 너무 많거나 변동이 심할 경우 추세선을 삽입하여 전체적인 경향을 파악할 수 있다.
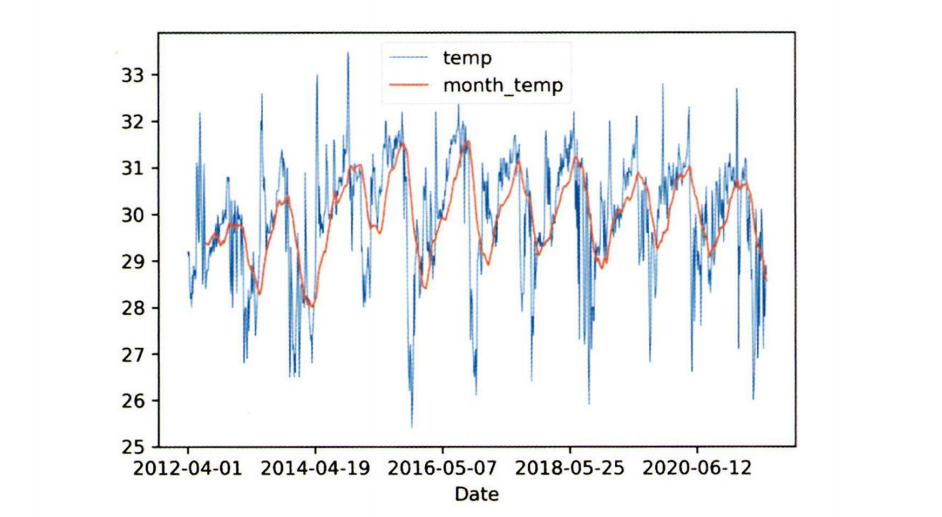 연속형 그래프 예시
연속형 그래프 예시
이처럼 가장 일반적인 방법인 이동평균 방법을 사용하여 추세선을 그릴 수 있다.
3-2. 분절형 그래프
분절형 시간 시각화의 경우 막대 그래프, 누적 막대 그래프, 점 그래프 등으로 표 현한다. 1년동안의 월 간격 단위 흐름 과 같이 시간의 밀도가 낮은 경우에 활용 하기 좋은 방법 이다.
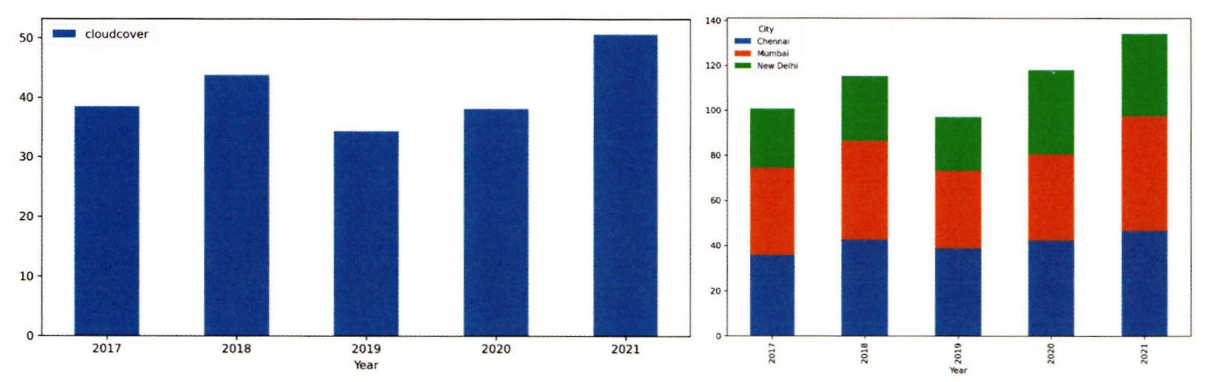 분절형 그래프 예시
분절형 그래프 예시
4. 비교 시각화
그룹별 차이를 나타내기 위한 비교 시각화 는 데이터가 간단하면 막대 그래프만으로도 충분히 표현 할 수 있다. 하지만 그룹별 요소가 많아지게 되면 보다 효율적인 표현 기법을 사용해야 한다.
4-1. 히트맵 차트
히트맵 차트는 그룹과 비교 요소가 많을 때 효과적으로 시각화를 할 수 있는 방법이다.
 히트맵 차트 예시
히트맵 차트 예시
4-2. 방사형 차트
방사형 차트는 여러 개의 양적 변수를 비교하며 유사한 값이 있는 변수를 시각화하거나 변수 사이에 이상값이 있는 경우 유용하다.
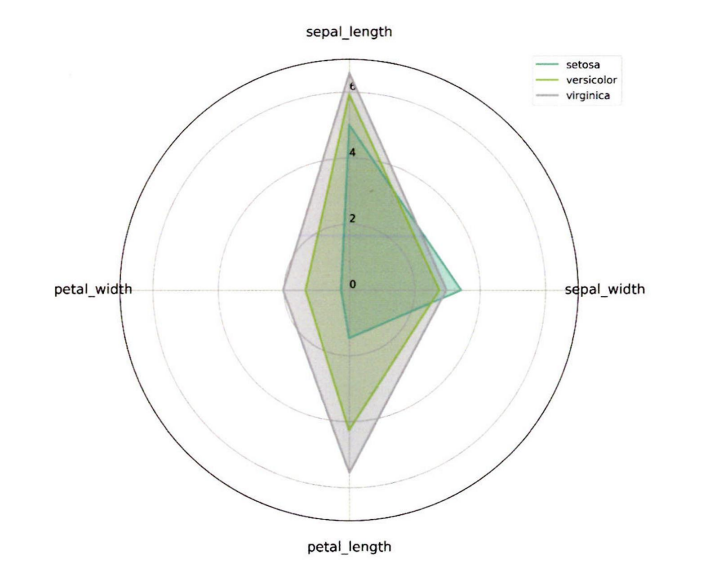 방사형 차트 예시
방사형 차트 예시
4-3. 평행 좌표 그래프
여러 변수를 평행으로 배치해서 수치를 표현하는 그래프이다.
정규화를 통해 차이를 부각 시킬 수 있다.
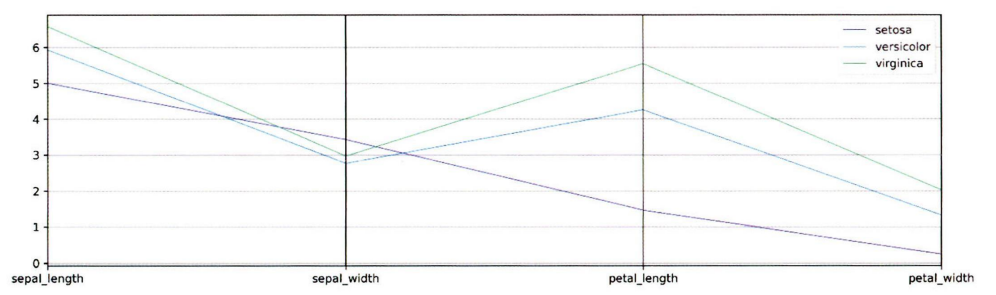 평행 좌표 그래프 예시
평행 좌표 그래프 예시
5. 분포 시각화
분포 시각화는 연속형과 같은 양적 척도인지, 명목형과 같은 질적 척도인지에 따라 구분해서 그린다.
5-1. 양적 척도
히스토그램은 겹치지 않는 변수의 구간 을 동일하게 나뉘서 구간별 도수를 막대그래프로 표현한다.
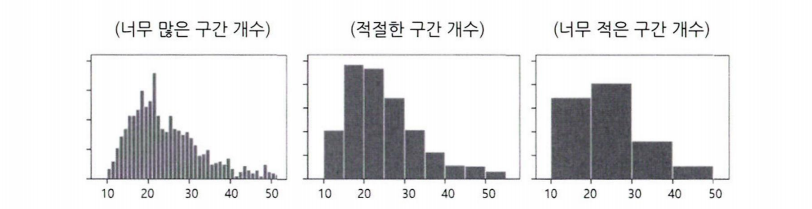 히스토그램 예시
히스토그램 예시
5-2. 질적 척도
변수 구성이 단순한 경우 파이차트나 도넛차트를 사용한다.
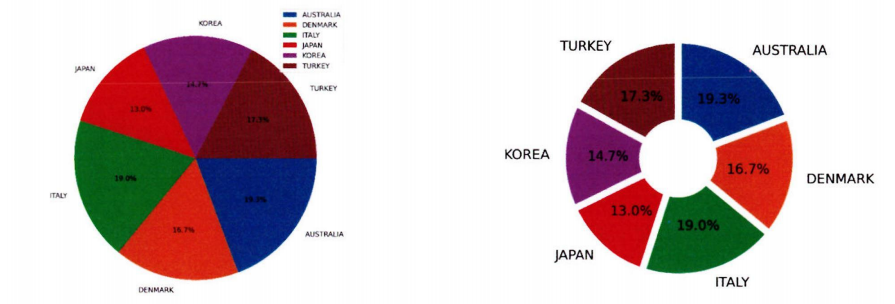 파이, 도넛 차트 예시
파이, 도넛 차트 예시
이외의도 트리맵 차트, 와플 차트 등이 있다.
- 트리맵 차트: 사각형 안에 사각형을 쪼개어 분포를 표시한다. 위계구조와 비율을 시각적으로 표현한다.
- 와플 차트: 일정한 네모 조각으로 분포를 표현한다. 위계구조는 표현 못한다.
6. 관계 시각화
산점도는 두 개의 변수 간 관계를 시각화 한 그래프이다.
산점도를 그릴 때는 극단치로 인해 주요 분포 구간이 압축되어 시각화의 효율이 떨어질 수 있으므로 극단치를 제거하고 그리는 것이 좋다.
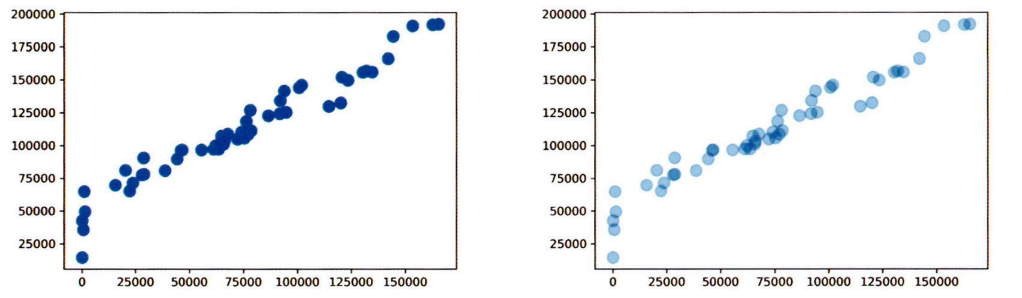 산점도 예시
산점도 예시
7. 공간 시각화
실제 지도 위에 데이터를 표현하는 방식이다.
지도를 확대하거나 위치를 옮기는 등 인터랙티브한 활용이 가능하므로 거시적에서 미시적으로 진행되는 분석방향과 같이 스토리라인을 잡고 시각화를 적용하는 것이 좋다.
7-1. 공간 시각화 다양한 기법
- 도트맵: 을 찍어서 해당 지역의 데이터분포나 패턴을 표현한다.
- 버블맵: 버블차트를 지도에 옮겨 표현한다.
- 코로플레스맵: 단계 구분도라고 하며, 데이터 값에 따라 색상과 음영을 달리해 표현한다.
- 커넥션맵: 지도에 찍힌 점들을 곡선 또는 직선으로 연결하여 지리적 관계를 표현한다.
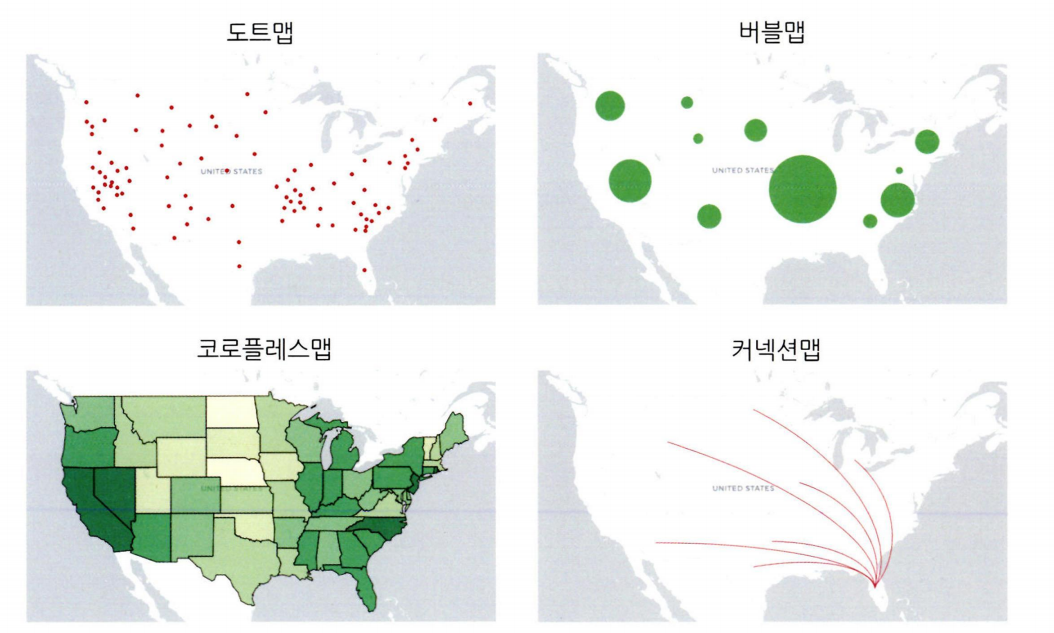 공간시각화 예시
공간시각화 예시
8. 박스 플롯
박스플롯은 네모 상자 모양에 최댓값과 최솟값을 나타내는 선이 결합된 모양의 데이터 시각화 방법이다.
하나의 그림으로 양적 척도 데이터의 분포 및 편향성, 평균과 중앙값 등 다양한 수치를 보기 쉽게 정리해 준다.
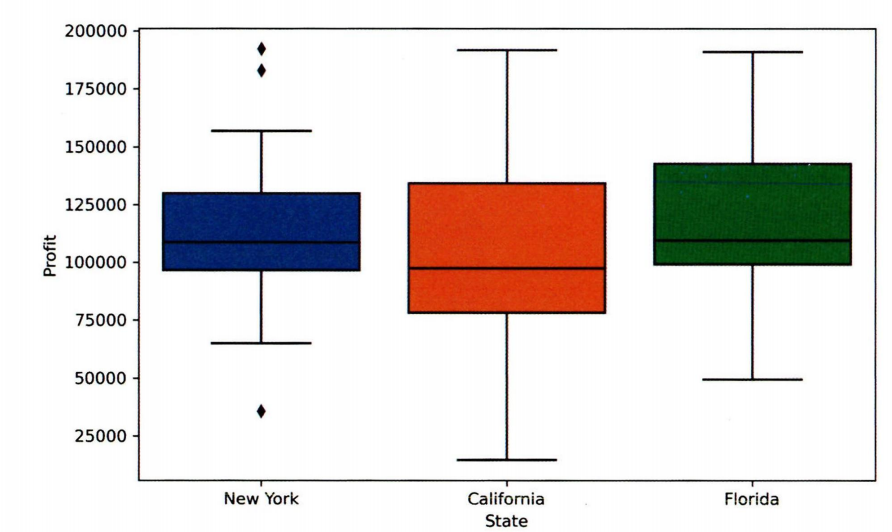 박스 플롯 예시
박스 플롯 예시
데이터의 대체적인 분포 형태를 쉽게 확인하기 위해 사용하며 카테고리별 분포를 비교할 때도 유용하게 사용한다.
8-1. 박스 플롯 구조
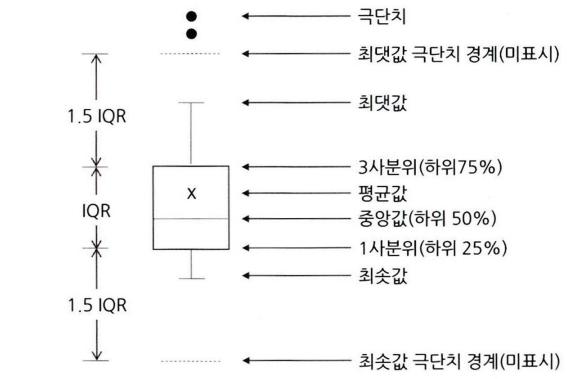 박스 플롯 구조
박스 플롯 구조
- 최솟값: 제1사분위에서 1.5IQR을 뺀 위치
- 제1사분위(Q1): 25%의 위치
- 제2사분위(Q2): 50%의 위치(중앙값(median)을 의미)
- 제3사분위(Q3): 75%의 위치
- 최댓값: 제3사분위에서 1.5IQR을 더한 위치