[금융전략을 위한 머신러닝] 6. 강화학습
아래 내용은 “금융전략을 위한 머신러닝” 책을 공부하며 정리한 내용입니다.
Chapter 09. 강화 학습
강화 학습: 이론 및 개념
 강화 학습의 개념
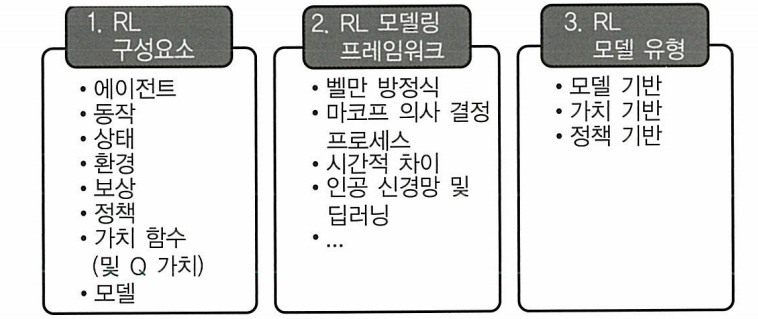
강화 학습의 개념
강화 학습 구성요소
- 에이전트: 동작을 수행하는 본체
- 동작: 에이전트가 환경에서 수행 할 수 있는 동작
- 환경: 에이전트가 속해 있는 세계
- 상태: 현재 상황
- 보상: 에이전트가 마지막으로 수행한 동작을 평가하기 위해 환경에서 보낸 즉각적인 반환
 강화 학습 구성요소
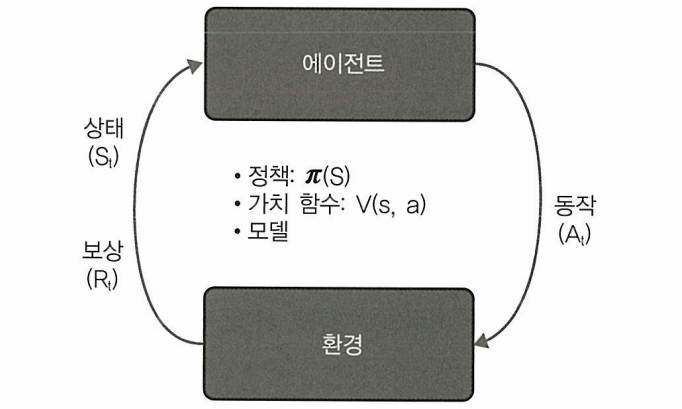
강화 학습 구성요소
강하 학습의 목표는 실험적 시도와 비교적 간단한 피드백 루프를 통해 최적의 전략을 학습하는 것
거래에서의 강화 학습 구성요소
에이전트
에이전트는 거래 에이전트이다. 에이전트를 거래소의 현재 상태와 계정을 기반으로 거래 결정을 내리는 인간 거래자라고 생각 할 수 있다.
동작
매수, 보류, 매도
보상 함수
실현된 손익. 또는 샤프 비율, 최대 손실률 등
환경
거래소.
강화 학습 모델링 프레임워크
벨만 방정식
가치 함수와 Q 가치를 즉각적인 보상과 할인된 미래 가치로 분해하흔 방정식 집합을 나타냄
보상함수(R), 미래 보상(G), 가치함수, Q가치의 관계를 사용해 도출
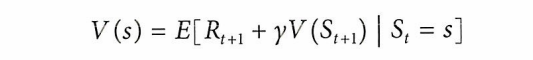 벨만 방정식
벨만 방정식
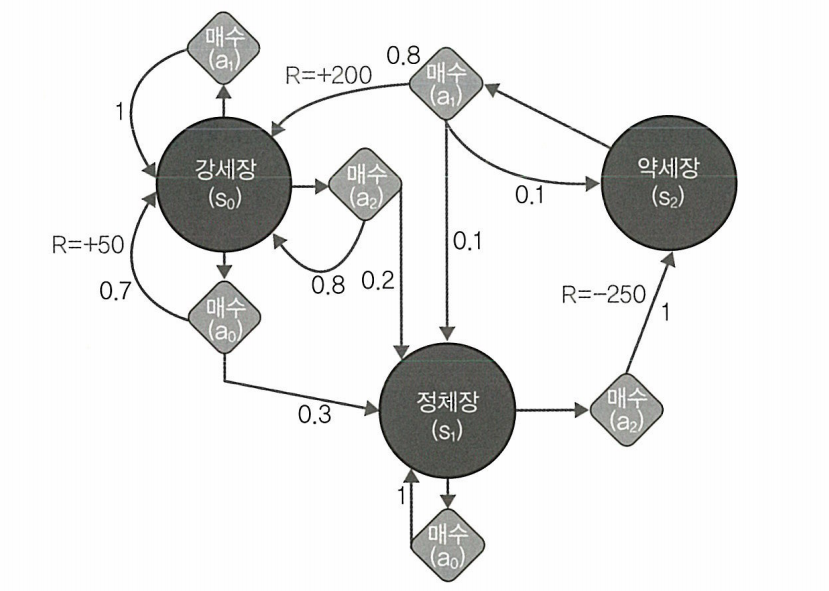
마코프 의사 결정 프로세스
MDP 는 다섯가지 요소로 구성된다.
S: 상태 집합 A: 일련의 장독 P: 전환 확률 R: 보상 함수 y: 미래 보상에 대한 할인 계수
 마코프 의사결정 프로세스
마코프 의사결정 프로세스
This post is licensed under CC BY 4.0 by the author.